Synk - Q1 2020 Update
Time for another bi-yearly quarterly update on the progress of Synk and issues that are currently attempted to be …

Hello again! There has been a lot going on in regard to D20Kit and Synk and most importantly version 0.2.0 is live! This version brings a few big improvements to the resource ledger for Synk rooms, the resource selector, and huge improvements of the realtime backend. Starting with version 0.2.0 it is now possible to directly upload the audio you want to use. With this update the previous resources that used external URLs, not including the audio catalog, will no longer work. I don’t expect this to affect too many ledgers.
If you haven’t already join our Discord to keep up to date when changes are announced! Join here!
Being able to preview tracks is a critical component to build your arsenal, this update includes some reliability updates in that previews now are guaranteed to only have one playing at a time and keep the background muted only as long as you’re attempting to preview. You also no longer have to hold your mouse over the button to remain listening. If you preview and haphazardly change the screen away from the preview button it will now unmute the main stage and kill the playing preview as well.

The resource ledger is your personal collection of tracks that you find most fitting for the specific campaign you are trying to run. Sometimes it can get a little cluttered with many different tracks and the old resource bank had some serious speed issues and overall was a chore to use. The new version is now correctly themed with the other components.
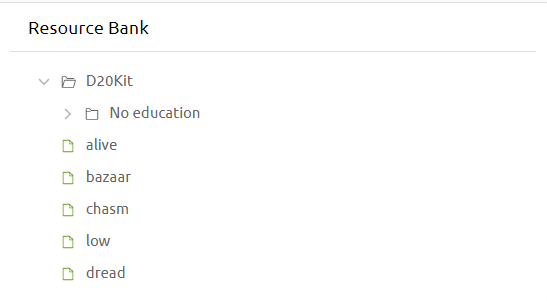
Folders of resources can be navigated to and will list all tracks in that folder. The current version only allows you to modify the name. You can now also delete an entire folder instead of deleting the tracks one by one.
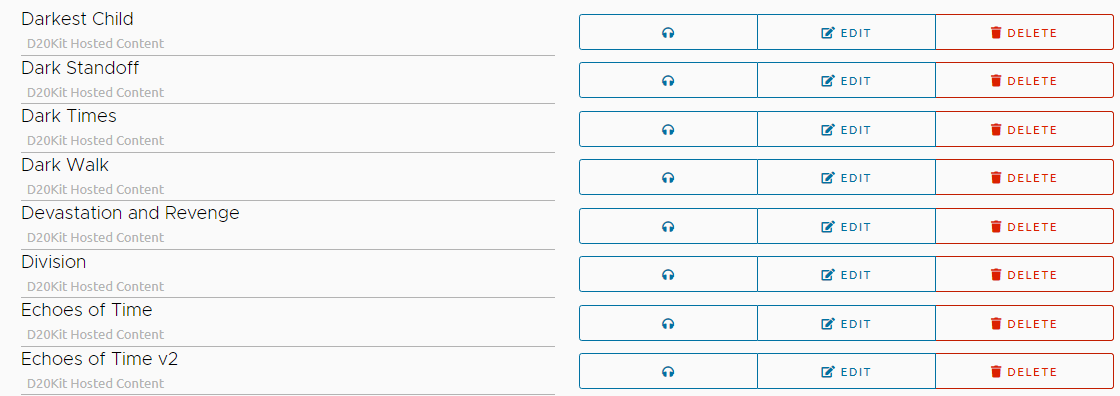

Resource creation no longer requires or allows providing a URL to create a resource. At the time of this post ledgers have a limit of 150 user tracks and the maximum upload is around 10MB. Previously catalog entries counted towards this limit and that is no longer the case!
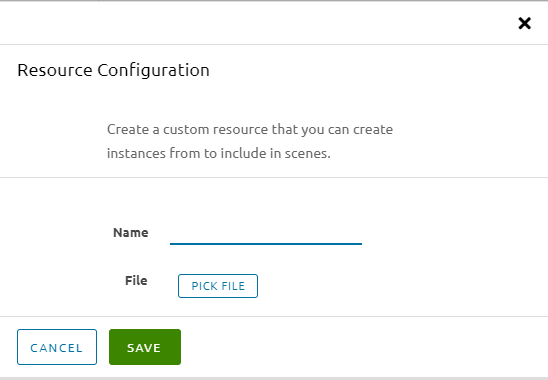
It is now possible to have completely private rooms either locked to yourself or with a password. This feature is for those who may want to try to livestream and not have to worry about the secrecy of your room id.
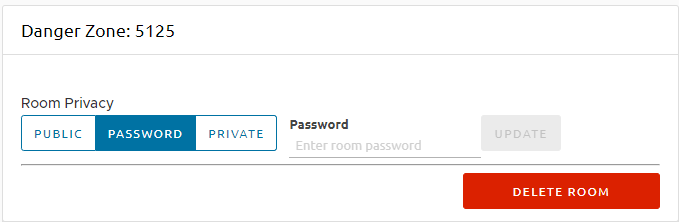
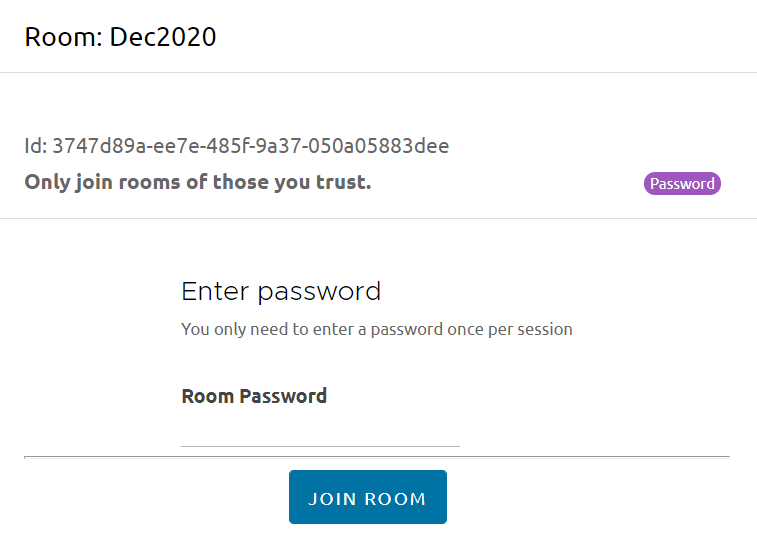
Adding resources to your scenes got a major facelift and no longer require you to remember an esoteric identifier (UUID) in order to add it. You may now also preview the track to make sure what you’re adding is exactly what you wanted.
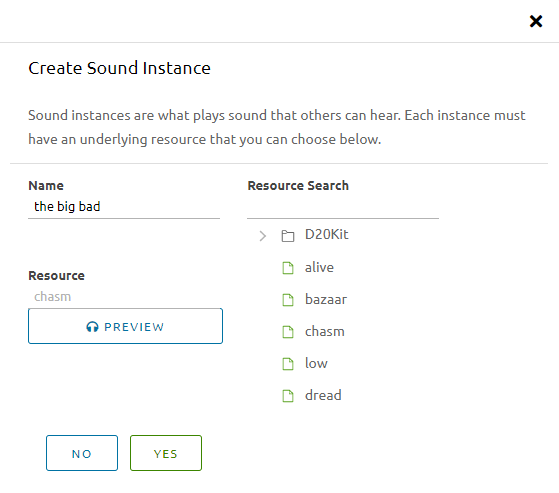
Synk Dec 2020
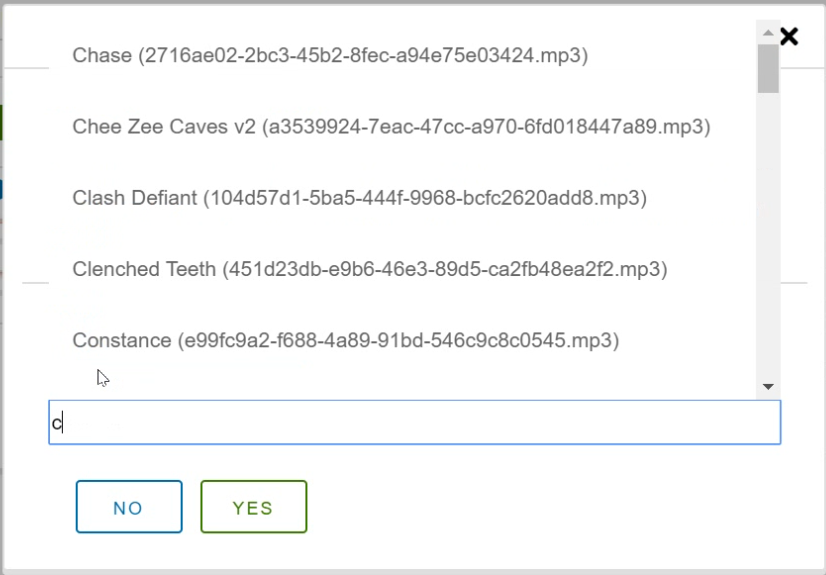
Synk Pre-Dec 2020
Concord is the name of the new realtime system that has been purpose built for Synk and other realtime related projects for D20Kit. It has an amazing ability to scale to potentially thousands of events for thousands of parties. There isn’t really much of a visual aspect to this system as it’s completely audial with Synk! However one component is now powered much more reliably with Concord and that is showing who is in the room.


Each user still has a randomly generated identifier but as a logged in user your own pill will be green, for guests it will be a light cyan color. The owner of the room will have a nice crown to signal that they are somewhat more powerful.
The authentication colors also carry over to the top right of the header bar where the plug and headphone are. These are to signal whether you’re authenticated along with the visible “Logout” button.
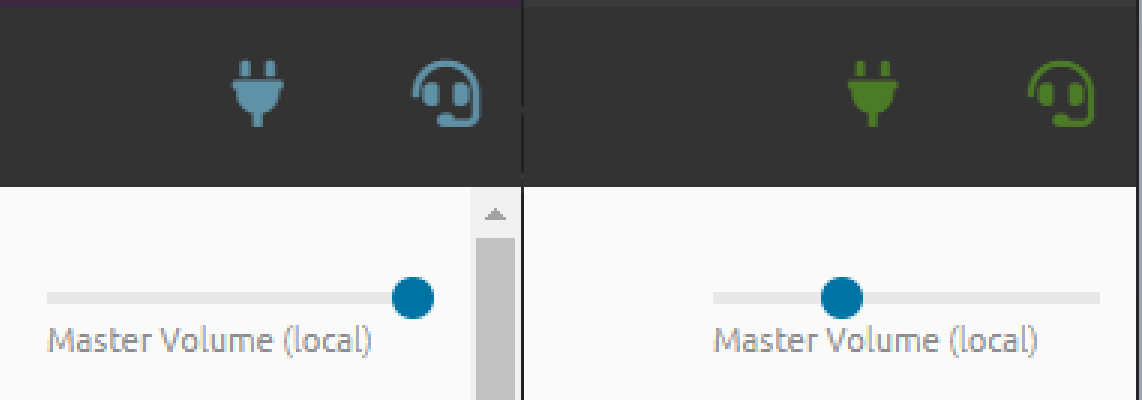
In case you were curious, yes, it is possible to have an absurdly high number of people in the same room that really shouldn’t be there.
In case you thought 40 was a conservative number you’d be right. I can’t actually have more than 50 without being rate limited (a good thing).
Disclaimer: This segment is technical leaning and may not make sense for most regular users. Feel free to skip to “Looking Forward”
With much hassle and a great struggle most of D20Kit is completely described in infrastructure as code. This is done purposely because this project has been through a total of 3-4 cloud migrations between AWS, GCP, Digital Ocean, Linode, and now Azure. Each step along the way grew the requirements of what platform I was trying to target.
Professionally I’m a Software Engineer with a DevOps background. So naturally like most engineers, I wanted to play with complicated and expensive technologies that are fun. Well, one flaw is I don’t have VC funding and I lack the time to maintain a fleet of infrastructure. This led me down a path of enriching my experience with Chaos Engineering. It’s a fancy word which just means that I built D20Kit knowing that every component is unreliable and may shut off at any time. Nothing is safe as the network could die, the database could go away, concord could fail, an application server could crash, the cache could suddenly be purged, long running jobs can be preempted, and an entire node can suddenly vanish. There are many more issues that occur but any error along the pipeline will bubble it up to the relevant caller/client and the client will gracefully handle it.
This does mean that sometimes the reliability of the user experience is at stake. In creating D20Kit I consistently test the client reconnection logic for authentication, room joining, audio consistency, and more. Hopefully this shows in the current offering and that users feel they don’t actually notice any issue as it happens.
I work a full-time job outside of this project in order to be able to support the ongoing costs which I intend to make sure I keep low. With the bonus of building D20Kit atop the principal of unreliability I can take advantage of insane discounts with Azure spot pools. It’s not for the faint of heart though as there are a lot of components that can go wrong. I don’t recommend anyone new to building distributed or highly available applications attempt to go down this route. If you’re in for a challenge and ready to spend many hours debugging and constructing reliable ways to monitor your application, then I implore you to attempt to try. Just know you will fail, a lot.
At the time of this post, the infrastructure is almost completely managed by Terraform. I say almost as there are some components I do not wish to have managed by Terraform, namely the root domain registry (d20kit.com). I have a nameserver delegation which I terraform the relevant routes on and create CNAME aliases to point to the delegated DNS records. D20Kit uses a Traefik load balancer in orders to provide certificates and automagicly forwarding for ingresses defined within a Kubernetes cluster.
This Kubernetes cluster is integrated with an internal CI system (not custom built, don’t build your own) that will test and deploy to a staging environment automatically. CI allows me to iterate and deliver updates even more quickly. Previously this was a completely manual process in which I’d build and push the container images directly to the container registry myself from my machine. This is now handled by an internal CI. I don’t particularly enjoy the idea of using products like CircleCI, Travis CI, or really any cloud based CI system. Firstly, because you have to give some pretty critical access to your software and your infrastructure. They can push or replace any image in your repository. You could be running an image which you originally thought was fine but the new pushed image has a sidecar process which siphons off your environment secrets. Secondly, they’re really expensive when you consider it’s charged per build-minute. It’s a great optimization tool but I can’t afford to pay an arbitrary fee on top, what if I run over? What I want to have my CI test every commit? Self hosting made sense for my use case.They could also publish malicious modifications to code repositories if you give it access to write that as well. For this purpose I purposely split my integrations and delivery systems. One thing I can rely on is that a CI system I run is less likely to betray me. It also allows me to be exceptionally portable as all I require is a k8 cluster and everything will work. It’s also a convenient separation from a process standpoint. The CD system I chose uses an opensource project called ArgoCD. This neat little tool allows me to define applications and repositories through k8 manifests (infra-as-code). Simply rewriting my existing manifests as helm templates allowed me to override the Argo applications with environment specific secrets.
The CI system has a few steps, but it primarily is responsible for testing the code, building the image, pushing the image, and triggering a new deployment action. This is done through two separate repositories where the CI cannot write to my application codebase but can freely modify the deployment repository. Indirectly through Argo and helm templates I can run validation checks in order gate any invalid deployment. With more effort I can create an even harder gap that requires the CI system to submit a PR for deployment that must be manually approved by the team in source control.
What all this jargon basically means is that I reduced what originally took about 30 minutes down to something that now takes 14 minutes total from commit to production. The main offender in wasting time currently is building the Angular client.
Building within the framework of unreliable software means that truly all components need to be resilient to having that resource suddenly become unavailable and avoid a crash. D20Kit is equipped with multiple systems that ensure the application itself is shielded from having to be concerned with a potentially unreliable network or even total node failure. Queries and most mutations are deterministic, meaning applying them multiple times does not cause issues. Authentication automatically refreshes the token on the client if you attempt to access something with an expired access token. Realtime message streams don’t close unless the application explicitly requests it, otherwise upstream it will attempt to rejoin and get back to a healthy state.
This means no matter how unreliable the system is if you’re able to reconnect once everything should continue working. Synk is built around deterministic audio. There is no live stream and there is no special logic that is gated inside Concord or Synk that must be exchanged to determine what should be playing. Synk only cares about mutations of a desired state. Like how Kubernetes works where components are described by manifests. Rooms are defined in a particular way that at time X track Y will be playing a Z time. This allows connection errors to be nearly invisible 99% of the time regularly. The only person that would experience the issue is the DM and they can simply click the button again to ensure their change is made. Clients upon reconnecting should resync the state to ensure they are aligned with what is meant to be playing.
This also means that the DM are themselves listeners of their own room. In order to ensure proper consistency, it doesn’t make sense to have separate ways to listen. The only difference is previewing tracks are entirely local.
2020 will always be a special year to me for many reasons but most importantly my ability to procrastinate writing the semi-annual quarterly post until the literal last day of the year. This year alone gifted me without the hassle of having to commute. This has given me an additional 3-4 hours a day to work on other projects besides my career and I’ve never been happier. I’m able to feel a challenge at my workplace and also feel productive on my own non-competitive endeavors.
Recently I’ve switched from my traditional Kanban approach to doing month-long sprints leveraging Agile. It’s not that previous approaches weren’t productive but after taking on the ability to add items to a sprint and challenge myself to estimate and manage priorities top to bottom has allowed me to more properly allocate my own time. At a high level I know how much time I have and I can pick specific tasks that I believe I’ll be able to accomplish within the time I have available that day. I’ve only been doing the approach for the month of December, but I’ve been able to complete roughly 2 (1.8) tickets per work day as compared to before where I’d have long stretches of unproductive tickets because they were overly complex and not easy to estimate.
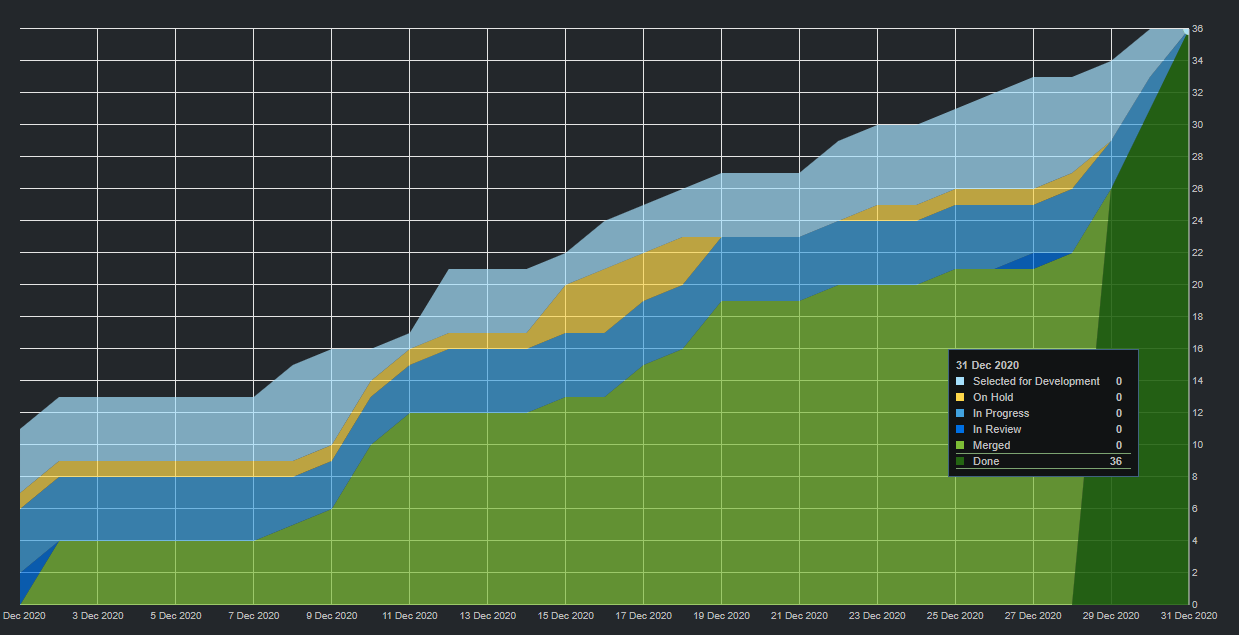
Dec2020 Sprint
You can almost see exactly when 2020 hit the fan in the chart which tracks issues since Synk was a proof of concept. To put the graph into perspective, the number of tasks completed in the year 2020 is more than what was done in 2-3 years. This is partly because of the 3rd major rewrite into a framework called NestJS. This framework provides a nearly identical development experience to Angular which is the frontend I use. I’m able to not have to context switch in order to understand the structure between the two codebases. A win!
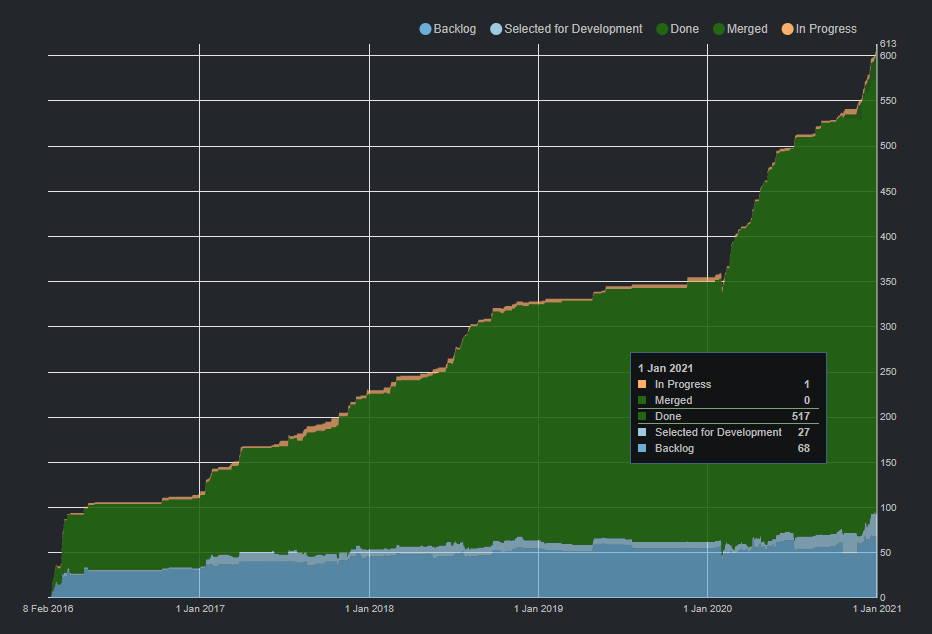
Synk & D20Kit cumulative flow Feb 2016 - Jan 2020
Lines of code are never a good measurement of but for the sake of completeness I feel there must be at least a small mention about the line stats. As of the time of this post the backend is at least 9,400 lines of code. Now before other engineers balk at that number I must mention that like Angular, NestJS leverages a lot of decorators. So many in fact that my controller functions are a little messy with decorators.
@Get('/:id/access')
@ApiOperation({ summary: 'Get access level'})
@ApiTags('synk:room')
@ApiOkResponse({ description: 'User can access room'})
@ApiBearerAuth()
@UseGuards(JwtAuthGuard({ required: false }))
async getRoomAccess(
@Param('id') roomId: string,
@User() user: UserModel,
){
// ... secrets ...
}
So just to define the function is 10 lines of code. This is true of most controller functions and model definitions and there are a lot of defined interfaces for the data. The backend is built entirely leveraging the IoC container that NestJS provides so that everything is mostly testable.
The frontend is strangely even more complicated than the backend (UI is exceptionally difficult to keep consistent with audio) coming in around 14,000 lines of code. Progress started on this version roughly around November/December of 2019 and since then has had more than 23,000 lines written. This gives me an average of writing roughly 60 lines of code per day. This metric is actually a worthless method but I think conceptually it’s a testament of how little time I waste maintaining infrastructure when I can just state through manifests what I want my infrastructure to be.
The next big version of D20Kit should include some more major improvements to the management and maintenance of the product itself. I will be spending some time building out the relevant panels to allow myself and other users manage the resources behind the applications. This includes stored files, rooms they own, ledgers, profile information, administrator modifications, etc.
I hope to give a facelift to the scene menu and really take a better crack at the catalog UI as it is currently horrendous. However, to give me some credit it was something I didn’t think would become the primary way people add audio.
The high-level goals besides to build out an administrative-like panel is to create a mobile-first controller mode that allows DMs to control the room audio via their phones. This will be useful for those that may not have multiple monitors or may want to dedicate specific screens to content. I will also be trying to create a vertical based UI that doesn’t look like garbage.
Another big desire I want to get through is to properly abstract away authentication users have upon resources defined within D20Kit. This is ambitious but will allow me to build the other projects much more easily when I have abstracted authentication primitives. For example, if I want someone to have access to play a subset of audio cues but not all. This is something that should be entirely doable but currently is not without a heaping pile of work just to allow that one task.
For those that stuck around until the bottom, here’s what you used to be able to do with the preview button. Also a collection of the progress that has been made over the years.
For those interested I’ve also compiled gource renderings of both the current iteration of D20Kit and the previous edition of Synk.
Time for another bi-yearly quarterly update on the progress of Synk and issues that are currently attempted to be …
Q1 was a slow quarter and had I had a 2,700 mile change of scenery in the meantime. This update won’t be very …