Synk - Q4 2020 Update
Hello again! There has been a lot going on in regard to D20Kit and Synk and most importantly version 0.2.0 is live! This …


The update post that should have happened in 2021
Hello! There has been so many changes to D20Kit’s entire frontend that this is going to be one lengthy post. First off between 0.2, 0.4, 0.5, and 0.6 there have been some major changes to nearly every part of the application. That insatiable trend of wanting to rebuild better every year. Attempting to scratch that itch and get the project moving somewhat forward rather than stagnate. There is a lot of changes to cover.
Let’s get right into it.
Originally in an attempt to keep a cohesive UI look I opted to use the Clarity Design framework
provided by VMWare. Unfortunately over there at VMWare they decided in their great wisdom
that ALL icons should be imported in code when one was imported. These were some heavy components. Something that caused
the original bundle size to bloat up to 7MB in development. However, this pales in comparison to including all of Fontawesome which reached 17MB.
After removing the absolutely massive
icon pack the main bundle is now roughly 500-600KB in development. A big improvement! Making the bundle
size smaller has not been a major priority to me as I’m trying to focus on features, but also keep code split,
anyone with a little Angular background can see that the major applications are at least split up
into lazy loaded bundles.
With the removal of these icons there had to be a replacement and because other portions of the application use Fontawesome it became the easy choice. I’m not a fan of their constant push for new versions that require a subscription, but what can you do? Use the free version of course! Then end up paying for it months later because you just want working icons. Throughout the application if an icon is suddenly a little different this is why.
Besides the Icons, I found myself fighting with Clarity itself. Sure it works great for VMWare applications, and it even comes with Angular components! Something that is hard to come by because everyone gushes over React. VMWare is a huge company, and they’re really slow at updating clarity to keep up with Angular. It creates gaps in development when some bug with their components grinds my entire work to a halt. The solution? Just drop Clarity. It works if you’re trying to build an admin panel, but the entire framework is so heavy that it’s not worth it for a more complex application that isn’t just forms. Removing Clarity and replacing it with tailwind meant I had to reinvent everything. With reinventing comes opportunities to learn Angular deeply.
There is still much work to be done in reducing the 2MB bundle size further, but that will require some more rewriting. Instead I hope to be building more features and try to optimize this at a later time.
Dropping Clarity meant having a massive hole of styling, just a blank page with text and images straight out of HTML 4.1. I’ve spent the better part of a year now with Tailwind and have a lot of great experiences with it. I have never felt more free in my designs. That freedom does come with some caveats as you duplicate style definitions all over your project. You end up recreating a lot of utility classes and attempt to compose the stylesheets in some reusable way.
I think the resulting product looks a hundred times better than before. I’ve been able to really show the tool in a way that I imagine working with it. Synk has been in rough development since 2016, and it has taken on many shapes, colors, and styles. When I migrated Synk into D20Kit I didn’t really consider how to integrate the synk tooling into the overall “package” that is D20Kit. Removing Clarity and substituting Tailwind forced me to confront this issue as with a blank slate I have to find how everything fits together.
There was a desire to have a single UI for the admin panel that was mostly drop in components. Something that didn’t require a lot of thought or maintenance to make it look half decent and functionality. Unfortunately while Nebula did make it relatively easy to build out the UI it required way too much screwing around with lazy loading styles with the old clarity frontend. This also created an unnecessarily late style load for the application which caused a white flash of unstyled content before the application loaded. My desire to make things easy ultimately makes Angular development more complicated than it has to be. Having worked with React in some capacity though, I don’t think this is unique to Angular. Component libraries really aren’t that great as there will almost always be a use case that isn’t covered. You will end up having to integrate your component with their component library and get stuck in lockstep with their slow release cycle.
While it was mentioned that the goal was to have a nice looking admin panel, that was somewhat of a low priority. It had to not be just black text on a white background with blue links. So what was hastily crafted up was a semi-nice looking unresponsive page.
It's not beautiful, but it works
While it’s not pretty, but it’s far better than the previous look… The best part is that it doesn’t need to be all that great since only admins are going to use it.
It turns out when a designer looks at your attempt to be cool with swooshes they grimmace and say “You could make it look so much better”. I’ve always had a vision on how I want to present the applications on the frontpage as a sort of way to generate visual flare, but first let’s address the elephant at the top. However the first attempt at the swoop, or in this case staircase, was noticeably pixelated.

At first, it didn’t bother me because I never had to look at it while developing but every time I went to the homepage there it was, sitting in plain sight. The staircase of ugly was the first thing that was seen besides the colorful logo floating, if a user had a small enough screen it might never been noticed, but it was destiny to just give up and try something with CSS. I wanted those nice crisp rendered lines, and maybe some subtle drop shadow.

Another new fresh look is the application splash below. The original look with just a single box never did feel like it felt right, it was too plain, and it wasn’t as eye catching. Especially for a landing page. This is now changed!
A little spoiler in this image but wanted to show the look with all the other applications one after another. With a cohesive color scheme of blue, orange, and green! Stay tuned for more updates on the next application in the works.
When you marry a designer you get a good feeling that they know design way better than you, and no matter how hard I try 99% of what I would make is going to be programmer-tier. Make the function then figure the form! The above 2021 homepage design was the beginning of what to display, but how to display it was graciously done by my wife.

A much needed facelift that looks absolutely stunning. There’s still more to do with the remainder of the application so stay tuned for more design updates on the rest of the application.
It has been a common complaint that people want to be able to upload more. More quickly, and even more quickly than that. So that’s what happened, uploading is as easy as dragging files onto the dropzone.

The overall design is still very beta and I think I’m going to take it a radically different direction, but for now it is possible to bulk add tracks to scenes as well. Function over form, right?
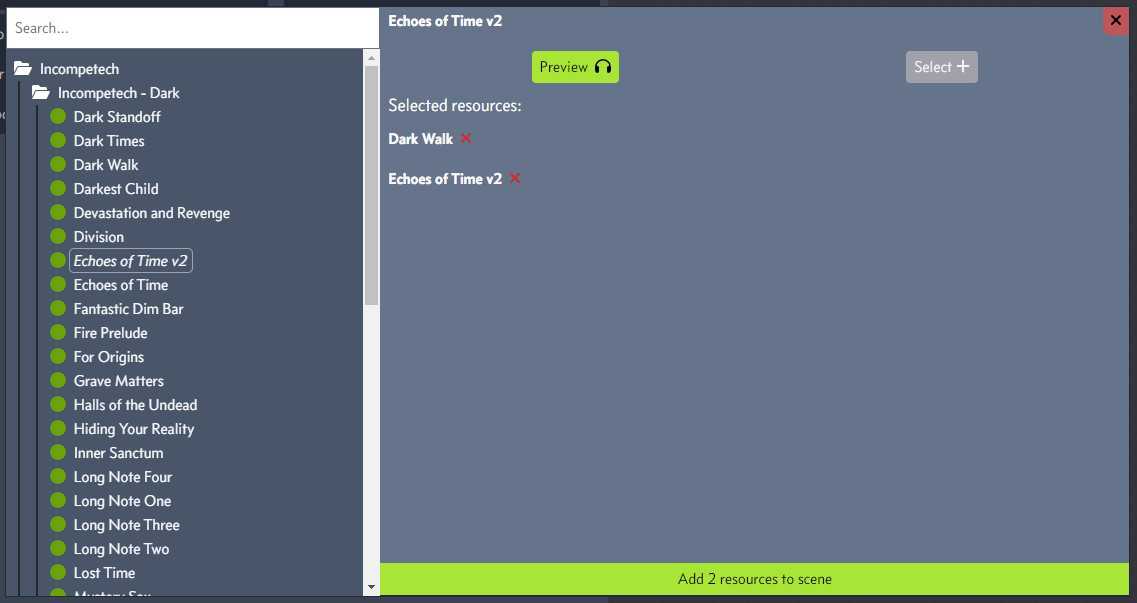
The catalog got a facelift and is going to be the future of how resources are handled within the application. The catalog will be searchable and incorporates hosted albums as well as your uploaded content. In the future I hope the above track creation is also done through the catalog. The catalog is also responsible for conveying license information and any potential restrictions you may have to follow. As of this post there are no albums outside the CC BY 4.0 license.
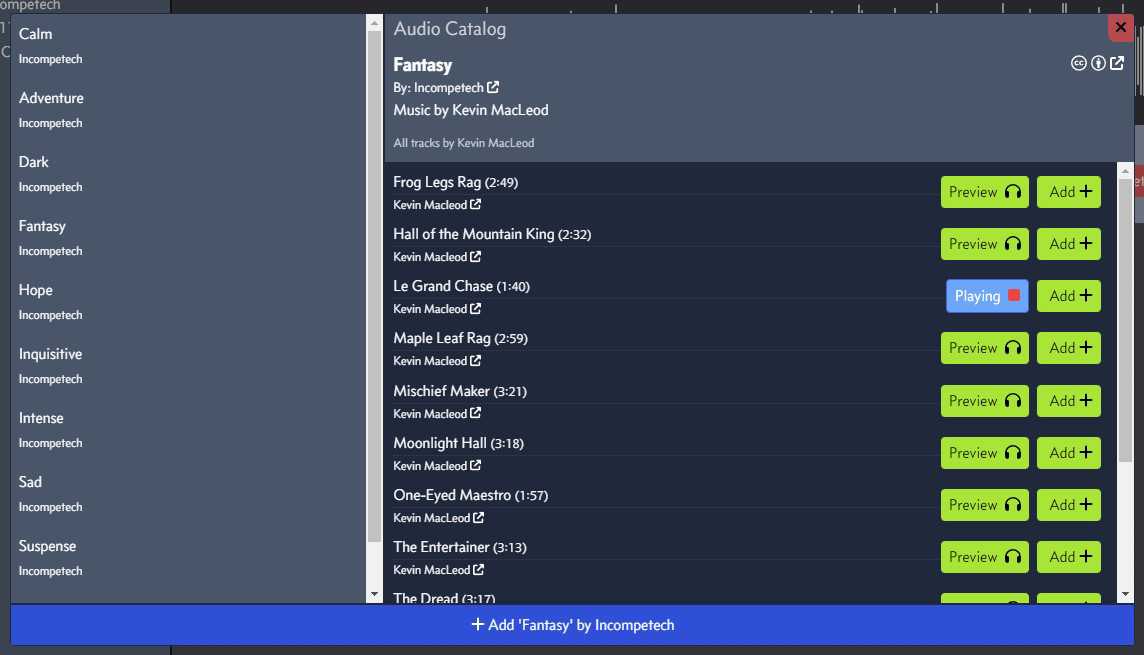
The resource ledger has been a difficult concept to manage and convey to new users, and I believe I’m going to phase out direct interaction with this in time. The work put in will not be for naught as audio waveforms are now front and center. You can scrub through the track to make sure everything sounds right. I hope to expand this use case and have track editing features available in time.
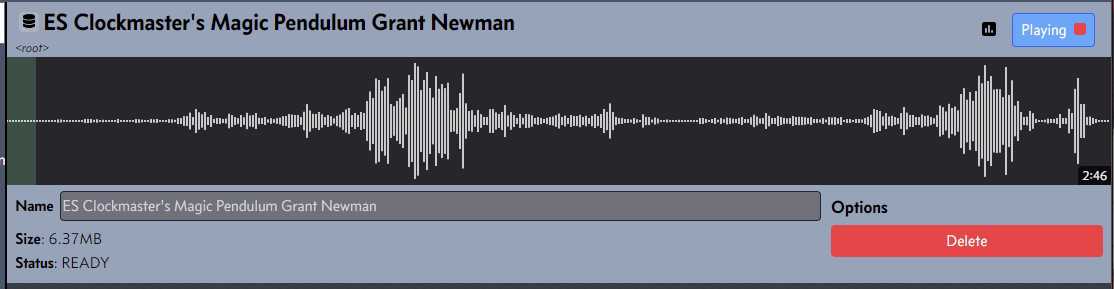
The editor has seen a lot of iterations, it doesn’t help that it is trying to convey a complex audio machine with all of its options in a simple UI. I’m still not happy with horizontal space usage and haven’t found a way to really incorporate a sound board, another critical part of the audio experience. Some new features landing in 0.6 are a fancy new gradient volume slider
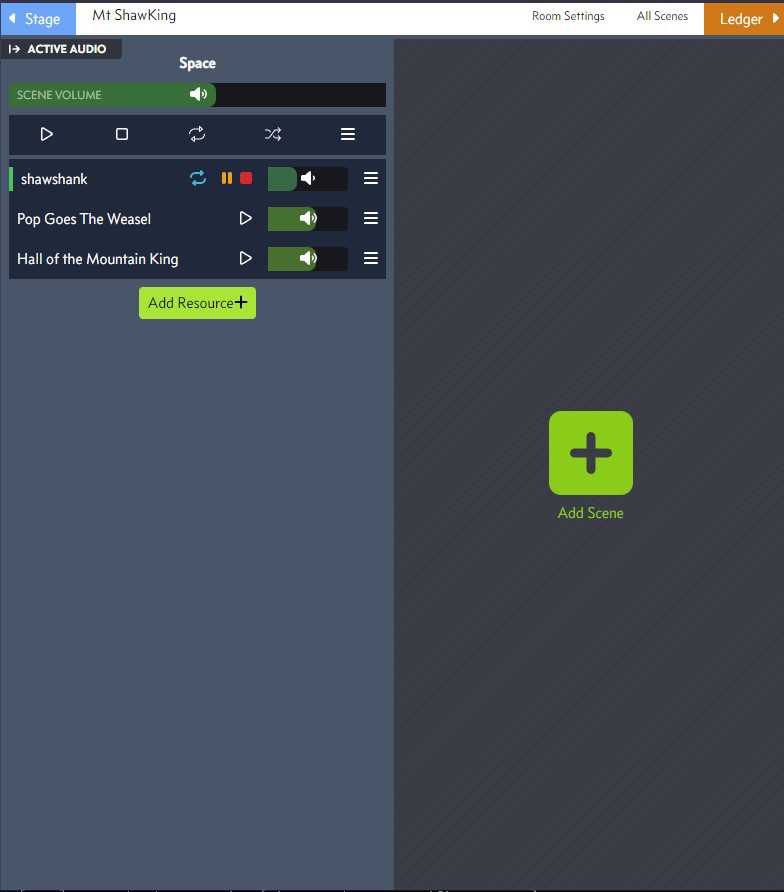
You’re now able to pause and resume tracks synchronously as well. No longer do you have to stop and restart a track in order to resume. This plays well for sequences where you need to resume a particular section of a track after stopping.
Within the editor there is another feature called scene sets. These are primarily used to organize related scenes together for ease of use in a pinch. You can imagine the use case for needing to switch between town ambiance to combat and those scenes would be organized through a town set and a combat set.
For the first time ever you are now able to actually edit the name of your room! This should have been available forever ago, but it just wasn’t. Now you can fix your typos and mistakes with ease. Just pop open the room settings and type away.
Now with the pretty updates out of the way it’s about time to talk about some the progress and many bugs that were discovered and fixed along the way. Below is the flow graph from the last post in December 31st, 2020. As you can see there is mostly a gradual incline of work done until the end of December 2021. What occurred?
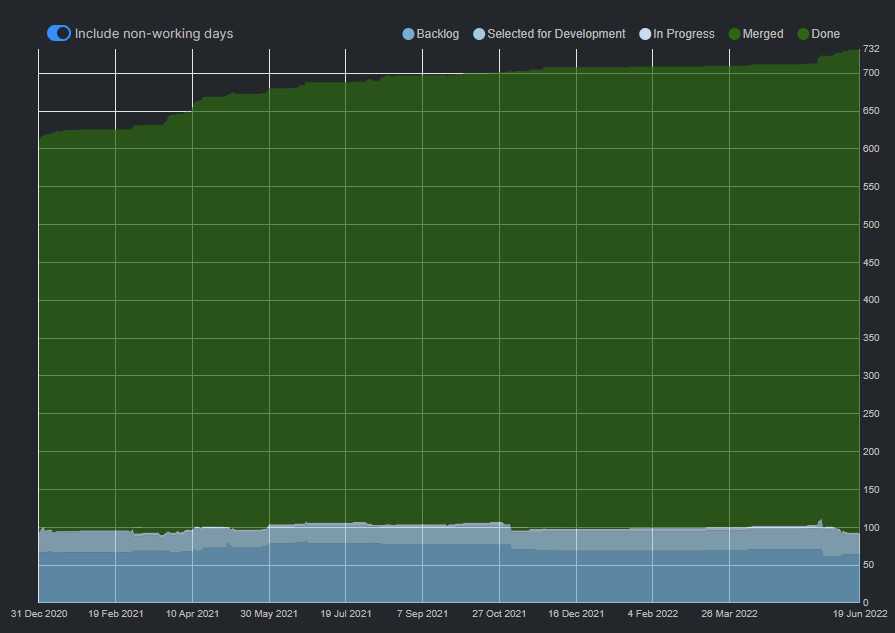
A job change and a massive undertaking to rebuild from scratch the entire audio engine. An eight-month project that I decided to approach like I would any professional problem. Creating diagrams for state machines and writing a document to cover the entire engine. With that it was quite easy to lay the blueprints down for a deterministic audio system that maintains consistent audio state amongst the participants. There is still one rare phantom bugs that I’m not able to root cause just yet, but it shouldn’t affect a majority of rooms.
The bulk of the work that I’ve been doing lately is refactoring and simplifying a lot of the maintenance layers I have to deal with when considering a multi-user application. For a normal business there is little care about cost overrun because funding has a few commas in the number. For my case I have to foot the bill every month, and this ultimately requires me to work another job to be able to sustain and afford this project. If you have a few dollars to spare, or you’ve found value from one of my blog posts or want to see the D20Kit project come to fruition. Why not consider joining my Ko-fi? (Shilling over)
So my primary concern is always making sure the cost is sustainable per month. Storage is somewhat cheap on Azure and D20Kit is not at the stage where I need premium storage where I’m paying $0.20/GB. I didn’t opt for the absolute cheapest and went with what azure calls “Zone Redundant Storage”. It comes with a nice price of $0.026/GB and with barely any users this comes out to not cost all that much. Taking off the rose-tinted goggles comes the harsh reality of orphaned files. Essentially a file reference that is lost or separated from the application. These are within potentionally hundreds or thousands of folders and files and there isn’t really a reliable way to know if it’s used without scanning the DB to see if it’s used at all.
Why not invert the chain of ownership? In doing so I opted to build out a sort of virtual storage system. This system is pretty simple in concept and extremely powerful in practice. It allows me to treat arbitrary data objects with virtual paths, similar to S3, as local or remote systems that are automatically maintained up until when the application designates the file isn’t needed anymore. This works on a claim system where merely creating the file is not good enough to establish ownership. Something or someone must then claim that file and describe its purpose. This is great metadata that is useful to also catch hotspots, abusive users, and bad applications. D20Kit takes a micro-monolith approach where the codebase is shared within a monorepo but is able to run as separate services. This unfortunately means there isn’t a reliable way to keep track of what server is actually writing through logs alone. There isn’t a fancy analytics dashboard for this yet, but you can be sure there will be in time.
So while the file is in this PENDING state it has a timer which will cleanup the file if it’s unused. Now this normally wouldn’t be an issue but because the infrastructure is inherently unstable certain requests may fail or certain files may get lost in the process. Especially if there is a network split or some sort of fail-over occurring at that time. The way the virtual filesystem handles consistency is through something called a Two-Phase commit. That’s good enough for D20Kit’s use cases.
In the end that’s the ultimate goal, provide a consistent blob storage to the applications without having to replicate storage concerns into every application. This is the true power of the virtual storage. It allows me down the line to hook up arbitrary blob storage solutions from Azure, AWS, GCP, R2, On-Prem, etc without any additional overhead for the client application to support them. Since files are referenced by virtual urls the clients will know how to solve the paths after discovering the server configuration. So what’s the next logical step?
This was the big update of version 0.4. It is now possible on the frontend to upload from anywhere in the application with ease, and due to the virtual storage on the backend any endpoint can accept any virtual upload with absolute ease with the assurance that the filesystem is consistent with what the application has stored! Currently, there is only one location to upload, and that was intentional because file uploading isn’t trivial in NestJS with permissions and other logic being required. I wanted a way to create a temporary upload area that was private and applications can then claim those files and store them internally to their own virtual storages. Think of it like a bunch of network drives and all users are uploading to that collection of drives, all the files on those drives have a deadline before they’re automatically wiped. As a user says to Synk, “Hey use this file for my resource”, Synk will go and look up in the upload registry for that file reference and get all the metadata of the original upload.
At first glance it just seems as if it’s a duplication of the virtual storage concept, and you’d be right at first. The subtle difference between the virtual storage system and the upload system is that the upload system uses the virtual storage to make the experience magical. It’s risky to upload files to a bucket without a reference, especially an in-flight upload. What happens if a user uploads the same files twice? The virtual storage shouldn’t be concerned with duplicate files, but it does track file hashes in case down the line there is some desire to consolidate exact-match files. When a user uploads the same file twice that hasn’t been claimed, why would there be a need to dump the data to the bucket again? The previous claim can just be returned with an extended deadline, thus saving space and bandwidth.
The endpoint also makes it trivial to upload multiple files in whatever structure that the application needs it in. Synk can upload multiple tracks and the backend can just automatically handle ingestion while keeping everything low cost, low storage, and consistent. This easily can scale to many users and extremely complex uploading situations. For security reasons the upload container is obviously private with no external access. Arbitrary files are technically still an issue with uploading, but there isn’t any specific way to download the file without it being claimed. The applications do a quick sanity check on the file (the same one had a user just uploaded to the endpoint) to check validity. It would also be pretty easy to add an upload target which would be required to specify. It would allow a user to specify validation scopes for the files they upload.
Now behold, a video from April 2021.
This major feature is the first step towards the second offering of the D20Kit as there will be a lot more components that will require uploading assets for customization. More on that in time!
A fun bug that was discovered is that if you play and stop an entire scene quick enough you’d run into the dreaded audio skipping issue. It is worse if you end up shuffling as every time you shuffle the reconciler is solved for a specific seed. If you clicked enough times and fast enough you’d end up with an ugly sounding issue where audio would cut out of nowhere and play another track at whatever time it was meant to be playing. This could be the beginning, end, or anywhere in between. This created a terrible experience and something that is more likely to happen than you’d think. When users want to shuffle to start with a specific song this issue would occur, but would also happen if the user didn’t mean to shuffle but wanted to repeat. These both would start a reconciler that would not properly turn over.
Enter 2022, a fresh year with great aspirations and desires to get this project back off the ground. It turns out that it still wouldn’t be anywhere close for another few months. First starting out with a horrid authentication issue where auth0 updated the secret key sizes. Then another issue with my self-hosted DB that suddenly went read-only in all environments. This year started out rough and D20Kit was unavailable for a large portion of this year due to these issues. As with all outages you take a moment to learn how much of the maintenance story you really want to continue doing. In the case of the DB, if it were an issue on all versions I would have been out of luck. Having to take it upon myself to find another DB solution that works within Kubernetes, and not many do, let alone on spot instances where they can vanish at any moment.
Redis has been a pain the entire time I’ve attempted to use it. Originally it was the core system to handle passing messages in between nodes so that the clients could get their updates. While it worked it always was bound to how much redis could handle. Meaning there was a strict limit on how many concurrent rooms I could service on a single redis node. Having originally done this with a hosted redis instance the costs were insane starting at $40/mo for the smallest production node. Could I do better? What was I really using redis for?
Concord was developed using Elixir and leverages phoenix as a backend channel to handle notifications messages throughout my ecosystem. This works great because of how efficient the underlying Erlang VM can pass messages to only nodes that are subscribed to a specific topic. Essentially extending this to the client meant I could share my backend notifications with the frontend and sufficiently keep the client within sync of the latest. There still is some necessary load testing to be done to see how much each concord process can handle, but it scales with my application instead of being a standalone instance.
The other segment I used redis for was a distributed lock on migrations and process queues. Now I could ultimately handle the tasks on a cron-schedule, but I don’t like to be too reliant on kubernetes specific primitives and try to keep the api requirements to the underlying infrastructure minimal. With that said etcd is pretty good at keeping the type of lease I’m looking for. Since these are internal-only systems the load is significantly smaller than any user traffic. This means I can reliably use etcd as a metadata store for what processes are executing.
So why switch? Why is redis such a pain? Well it’s because a single redis node is expensive to run managed, moreso for highly available. Trying to host a single node on a series of spot instances comes with the pain of losing the entire clusters locks. Why not just run the highly available series with sentinels? I tried, I really did, but the issue with attempting to run 3 redis nodes and 3 sentinels on spot nodes causes a lot of churn. When a node disappears the sentinels don’t really check whether that node is alive quick enough. So you’re left with 1/3 of your request failing until a failover occurs. If it could even attempt to failover and not get scheduled to a nonexistant node it would maybe start up. I could never rely on redis to do this process successfully, so anything to get off using it is better. Hence, using etcd and Concord to replace those two components.
The 0.6 revision attempts to break down what it means to be a part of a room made up of scenes. How does one know what to play, and where within the track to start? Universal time. It turns out clocks aren’t that reliable, but they’re reliable enough to not make a big enough difference to an audio experience. As long as the fidelity is kept high participants are happy.
The new audio engine attempts to strategically handle tracks that are defined to run by some function. That function is dependent on the type of scene at play. Regular tracks playing on their own are the simplest form of this. If the track has a start time we can infer what should be heard now. If you’re shuffling or looping we know what to shuffle and repeat. All based on universal time. So unless you purposely shift your clock you will hear the same thing across all participants. This is nothing new.
What is new is that Howler is great for a lot of things, but when it comes to coordinating tracks it leaves a lot to be desired and rolling my own webaudio framework for audio helps solve my specific problems with coordinating playlists and audio tracks. Efficiently loading and unloading of audio is possible in Howler but lacks cohesion with the observer of that audio instance. It became an issue if you were attempting to teardown a Howler instance while it was in the middle of loading, unloading, or a complex state change.
The reconciler mentioned above was a stop-gap solution to handle the inconsistencies with calls into Howler and what actually occurred. Rolling my own framework allowed me to strictly define how an audio state can mutate and keep that consistent with the rest of the application. This has made it possible to completely separate the audio engine from Synk and have it be used in a lot of other applications later.
Alongside this update previews no longer have their own side chain of audio infrastructure and rely on the audio engine. Which now abide by the master volume of the application.
There isn’t much going on here other than an attempt to reduce the dependency map and attempt to cash in on the supposed speed of fastify over express. Thankfully NestJS has a fastify adapter that simplified the migration. However, uploads were the complicated part as I no longer had Multer to automagically format and handle my files as it did with express. Creating a thin layer for the fastify version was sufficient to replace though, no additional code changes required.
Attempting to reduce the scope of external dependencies I dropped a lot of one-off tests and deps that were no longer used. This allowed the bundle size to shrink from 8MB down to 2MB as I kept cutting as much as I possibly could.
It’s not a secret that I like to overcomplicate my hosting setup to maximize the flexibility I have on my hosting provider. As of 2022 nearly every single instance I have to maintain is completely covered with automation scripts in terraform and pyinfra. Managed by pyinfra the Gitlab instance, Vault, YouTrack, instances become repeatable and easily upgradable. No more am I strapped to a single cloud provider for anything and can migrate any of these applications within a day.
What isn’t handled by pyinfra is maintained within Kubernetes. Each application has a CI process defined with Drone CI, this process does my testing and linting. Some other steps are taken to verify package integrity and block builds if there is a severe issue. Once that CI process is through it will increment the build by the relevant changesets. From those changesets and published container image ArgoCD gets notified and takes the manifests and deploys them to the staging environment first. If the build is successful and doesn’t have any immediate runtime issues the build is promoted to production. There are still additional components I’d love to include such as CI E2E testing, but it requires a bit more involvement in the build pipeline since a full chrome runner can be quite heavy.
Going from Terraform > PyInfra > Kubernetes > Drone CI > ArgoCD has been so easy to keep the latest changes in D20Kit actively available. I’d like to invest further into this ecosystem as I have had great success with it.
D20Kit has been a side project for the better part of the last 6 years. With multiple breaks and stints of work it has come together to be mostly reliable at this point. I don’t have a worry if concord, the app, kubernetes, or my DB goes down as I know I’ve run across a lot of instances and patterns that assist with making sure the system stays consistent. The next challenge will be taking on the Puppeteer project, which is not to be confused with Google’s puppeteer.
The next project being announced is Quill and the first tool within Quill is going to be puppeteer. The goal is to have your peers be able to customize and play their character with a puppet. This can be great fun as you are able to show more emotive expressions than one would be comfortable acting out themselves. This tool is great for those who want to have a more fun approach to dialog, or have your participants act out scenes. Puppeteer is going to be great for tabletop RPG streams as it gives a whole new level of production to your story.
There will be more revealed about Quill in time, especially as I finish the last of the small feature tickets still relevant for Synk.
Hello again! There has been a lot going on in regard to D20Kit and Synk and most importantly version 0.2.0 is live! This …
Time for another bi-yearly quarterly update on the progress of Synk and issues that are currently attempted to be …